Handling Retries in Messaging Systems
Adapting Enterprise Integration Patterns for Cloud Architectures

👋 Hi my name is Christian.
I am working as an AWS Solution Architect at DFL Digital Sports GmbH. Based in cologne with my beloved wife and two kids. I am interested in all things around ☁️ (cloud), 👨💻 (tech) and 🧠 (AI/ML).
With 10+ years of experience in several roles, I have a lot to talk about and love to share my experiences. I worked as a software developer in several companies in the media and entertainment business, as well as a solution engineer in a consulting company.
I love those challenges to provide high scalable systems for millions of users. And I love to collaborate with lots of people to design systems in front of a whiteboard.
I use AWS since 2013 where we built a voting system for a big live TV show in germany. Since then I became a big fan on cloud, AWS and domain driven design.
When messages are flowing through your system, it's crucial to handle retries effectively to maintain robustness and guarantee message delivery. With the right patterns and tools, you can build resilient messaging architectures.
In this article, we'll explore the world of handling retries in messaging systems by leveraging Enterprise Integration Patterns. These patterns provide a solid foundation for building reliable systems. With the help of AWS services, such as Amazon Simple Notification Service (SNS), Amazon EventBridge, and Amazon Simple Queueing Service (SQS), we can implement patterns like publish-subscribe channels or message broker and integrate them with a dead-letter-channel.
Understanding Publish-Subscribe Channels, Message Broker, and Dead-Letter Channels
These patterns play a significant role in facilitating communication within messaging and event-driven architectures. It's important to note that relying solely on publish-subscribe channels or a message broker does not guarantee a reliable flow of messages. There are situations where message deliveries can fail, such as:
Unavailable or Unresponsive Subscribers: Messages may fail to reach their intended subscribers if they are temporarily unavailable or unresponsive. For example due to network issues, system failures, or resource constraints.
Poison pill messages: Subscribers can perform validation checks on incoming messages to ensure they adhere to the expected format or criteria. If a message fails validation, the subscriber may reject it by throwing an exception, leading to a failed delivery.
Misconfigured routing: If routing rules within the messaging system are not properly configured, messages may not be routed correctly to the intended targets.
Dead-letter channels play an important role in improving the overall reliability of your system for certain failure types.
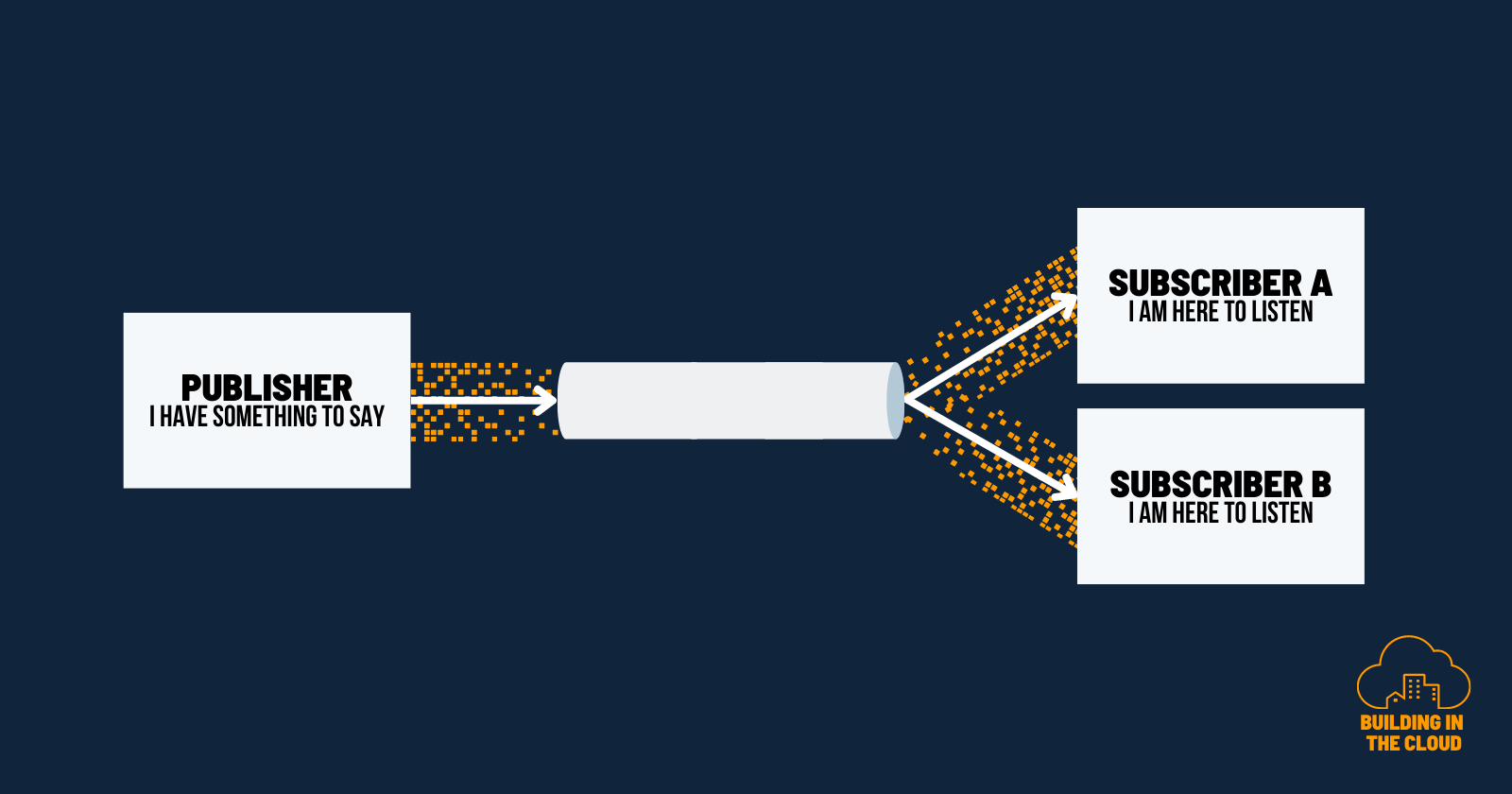
Publish-Subscribe Channels
Publish-subscribe channels broadcast messages to multiple subscribers. Publishers generate messages and publish them to the channel without knowing the identity or number of subscribers, allowing for loose coupling between components. Subscribers express interest in receiving messages by providing a dedicated output channel. In terms of message flow a publish-subscribe channel can be considered as a one-way street.
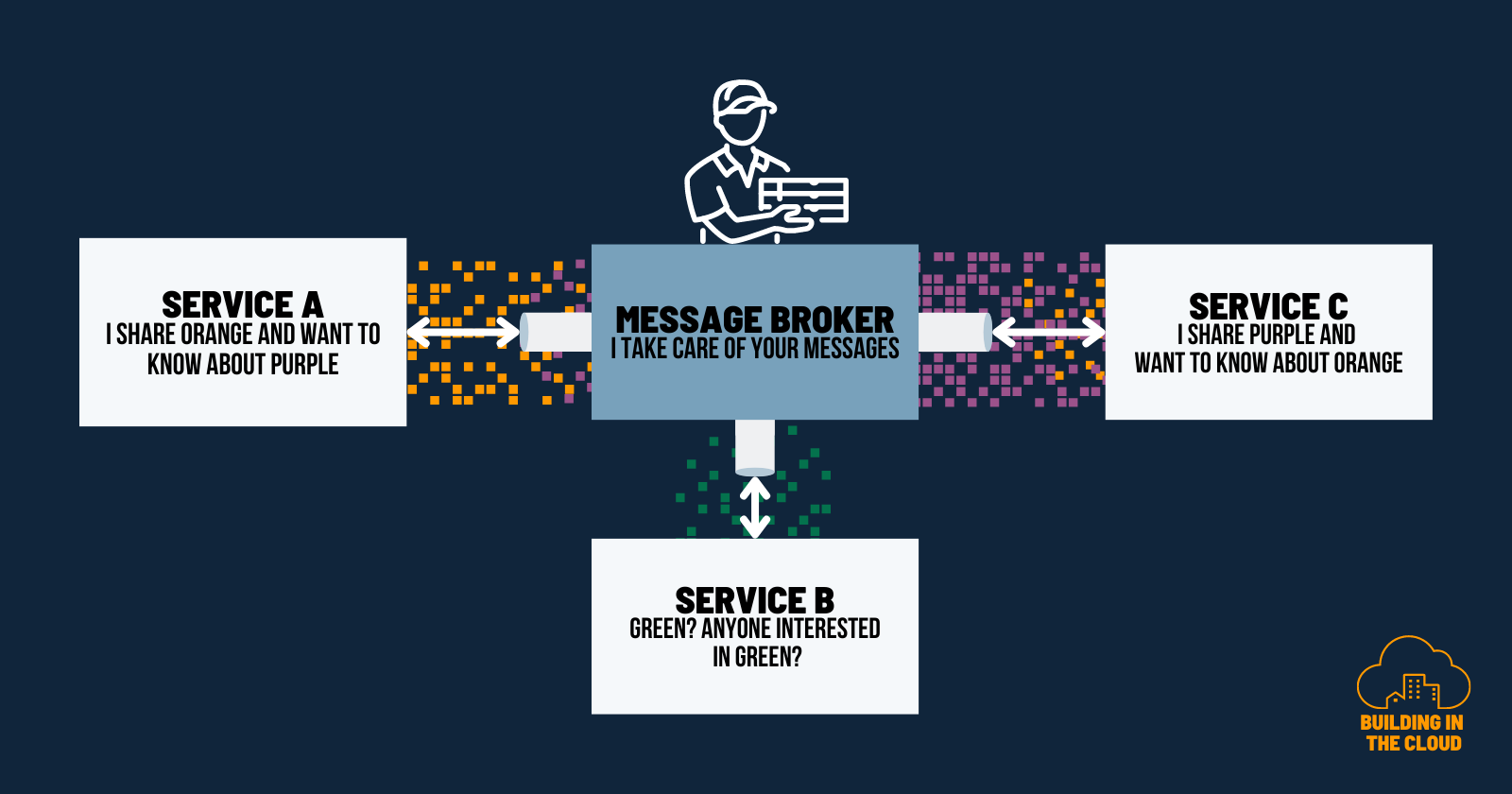
Message Broker
A Message broker serves as a central hub for messages in messaging systems. Often included with message router capabilities, several adapters, message filtering, message transformation capabilities, and a whole more of a messaging infrastructure, a message broker facilitates seamless communication between components. Messages can flow in any direction back and forth depending on the configured message routings.
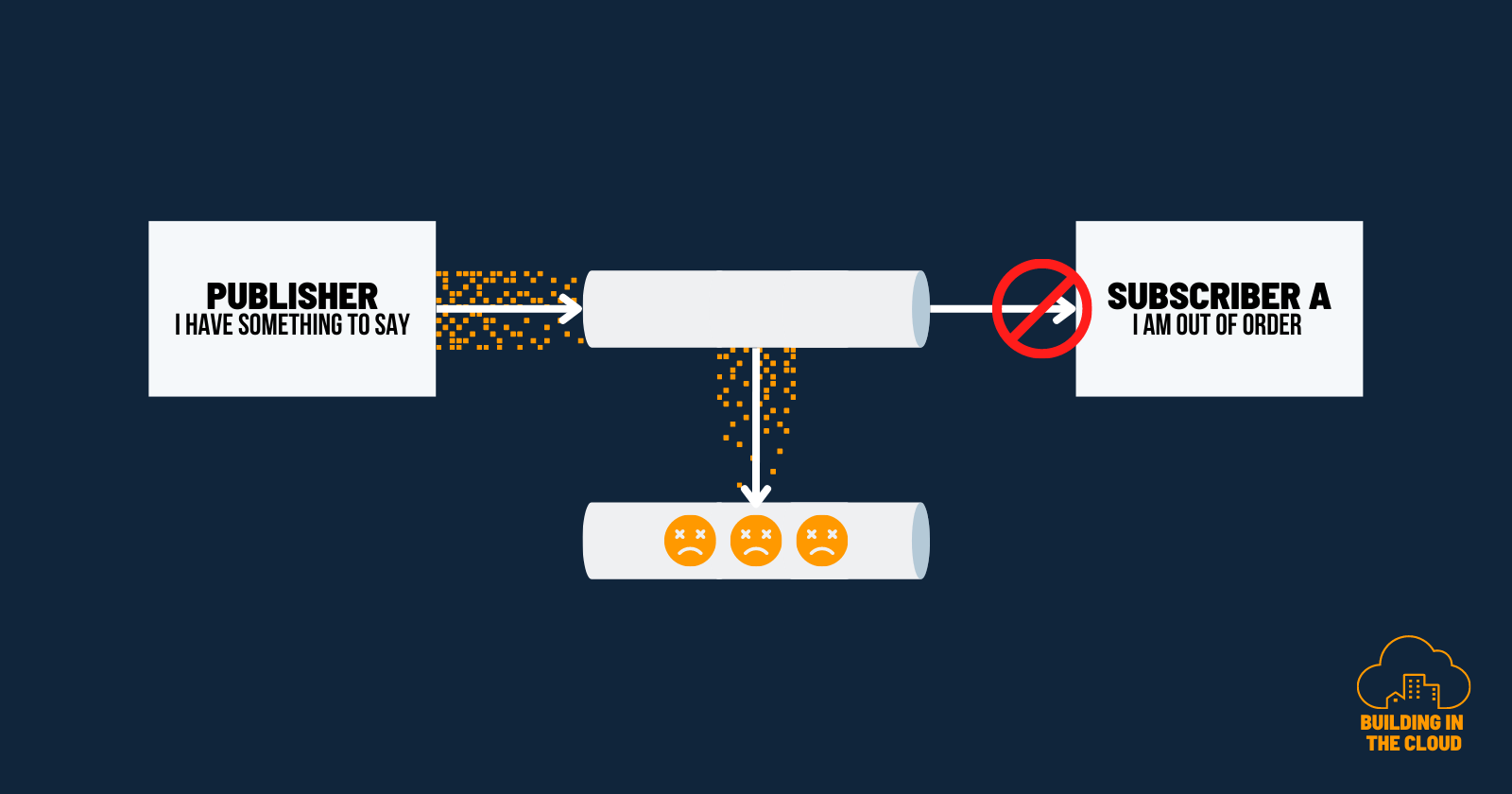
Dead-Letter Channels
To handle situations where message delivery to the desired destination fails, messaging systems incorporate dead-letter channels. Dead-letter channels act as a message target when a previous channel, such as a publish-subscribe channel or a message broker, detects that a message was not able to be delivered to its intended destination. In such cases, the source channels can direct them to a dead-letter channel.
Dead-letter channels provide an opportunity for further analysis and retries, enabling you to resolve issues that may have caused delivery failures. This enhances the overall reliability of the system.
Implementing Dead-Letter-Channels in AWS
Now that we understand the importance of dead-letter channels in improving the reliability of messaging systems, let's explore how we can implement this pattern in AWS using two popular services: Amazon Simple Notification Service (SNS) and Amazon EventBridge. Both services provide integration with Amazon Simple Queue Service (SQS), which serves as the dead-letter channel for capturing and handling failed events.
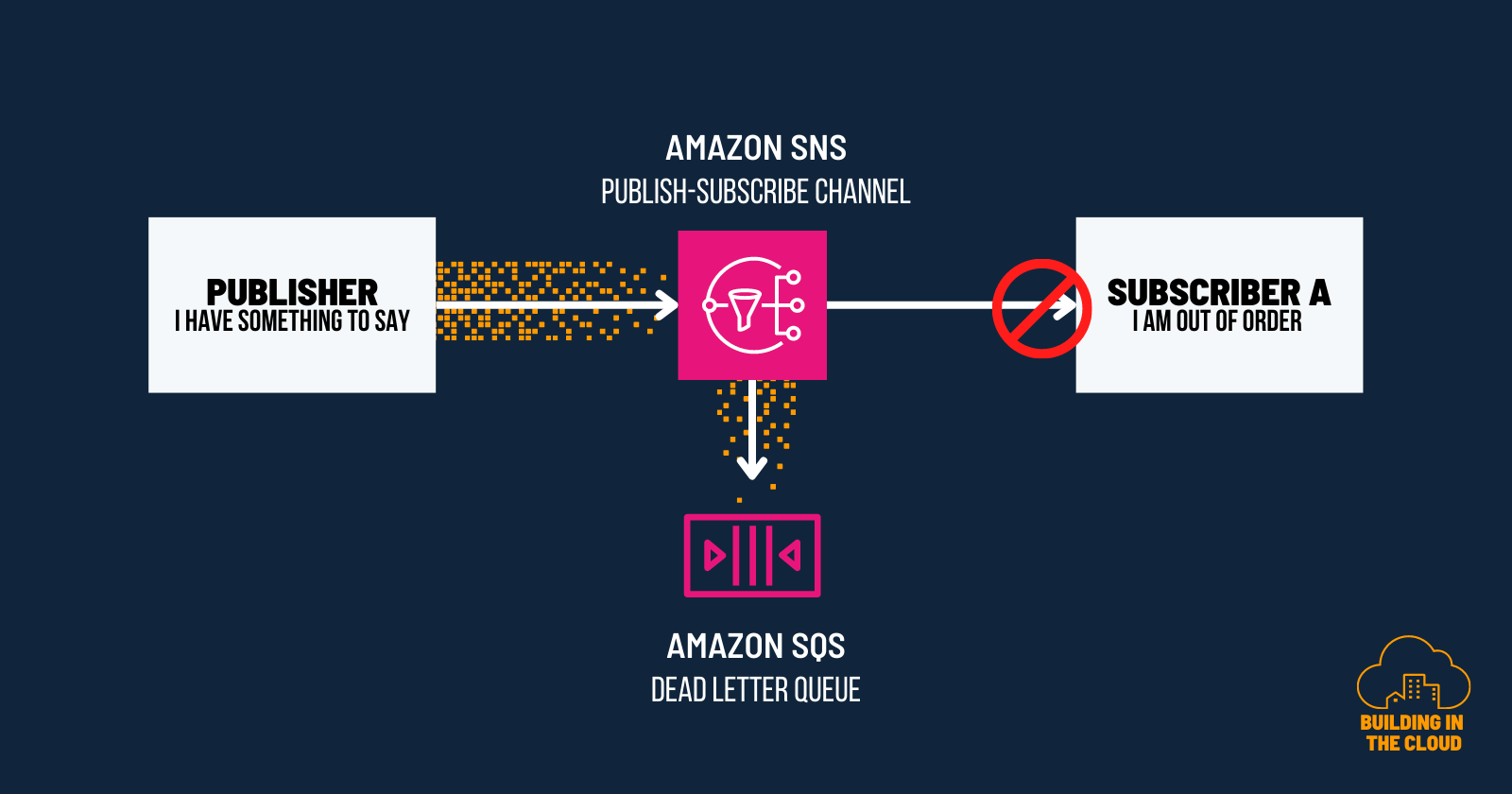
Amazon SNS as your Publish-Subscribe Channel
Amazon SNS acts as a publish-subscribe channel, allowing publishers to send messages to topics, while subscribers receive messages from these topics. When configuring Amazon SNS, you can set up multiple subscriptions within a topic to direct messages to different subscribers.
Amazon SNS comes with an implicit retry mechanism called delivery policies. This policy defines how Amazon SNS retries the delivery of messages when the subscriber is not able to process a message.
To incorporate a dead-letter channel for a specific subscription in the workflow, you can configure the subscription to integrate with an Amazon SQS dead-letter queue. This means that if a message published to a topic fails to be delivered to a particular subscribed endpoint, it will be sent to the associated dead-letter queue for that specific subscription.
By configuring dead-letter queues on individual subscriptions, you can ensure that failed messages are captured and processed accordingly, mitigating the risk of message loss and enhancing the overall reliability of your messaging system if delivery policies do not meet the required criteria.
The AWS Documentation gives good guidance on how to set up Amazon SNS dead-letter queues.
Amazon EventBridge as your message broker
Amazon EventBridge acts as an implementation of a message broker. When setting up Amazon EventBridge, you can define rules that determine how messages are processed and delivered.
Amazon EventBridge comes with an implicit retry mechanism called event retry policies. This policy defines how Amazon EventBridge retries the delivery of messages when a target is not able to process a message.
To implement a dead-letter channel you can configure the rules targets to integrate with Amazon SQS dead-letter queues. This allows you to specify a dead-letter queue at the target level, meaning that messages failing to be delivered to a specific target will be sent to the associated dead-letter queue if event retry policies do not meet the required criteria.
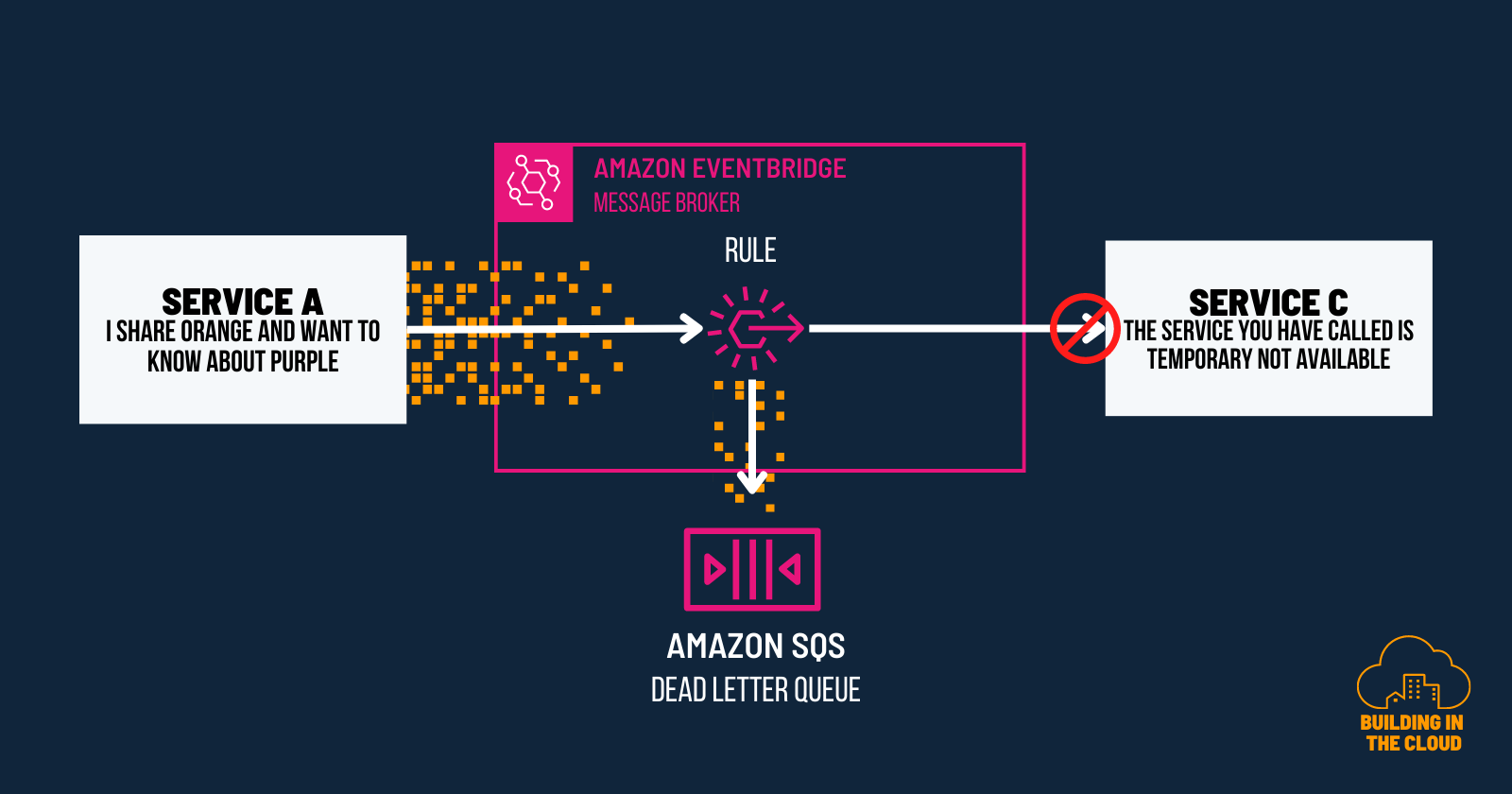
It is a bit hidden in the AWS documentation but here's how you can do it in a nutshell:
Set Up an Amazon SQS Dead-Letter Queue: Create an Amazon SQS dead-letter queue that captures events not successfully delivered to their intended targets. Make sure to add the required resource policies on the queue, granting Amazon EventBridge permission to write messages into the queue.
Create a rule: Begin by creating rules within EventBridge that specify the conditions for event processing. These rules can include filtering criteria, event patterns, or specific sources.
Configure Dead-Letter-Queue for a target: When defining the targets for your EventBridge rules, you can configure a dead-letter queue for individual targets within the rule configuration. This allows you to specify a specific dead-letter queue for each target, which will receive events that fail to be delivered to the intended destination. By configuring a dead-letter queue for a target, you ensure that any events that encounter delivery issues for that specific target are captured and redirected to the dead-letter channel for further analysis and handling.
This ensures that any messages unable to reach their intended targets are captured, allowing for further analysis or retry attempts to mitigate the risk of message loss.
Best Practices for Handling Retries
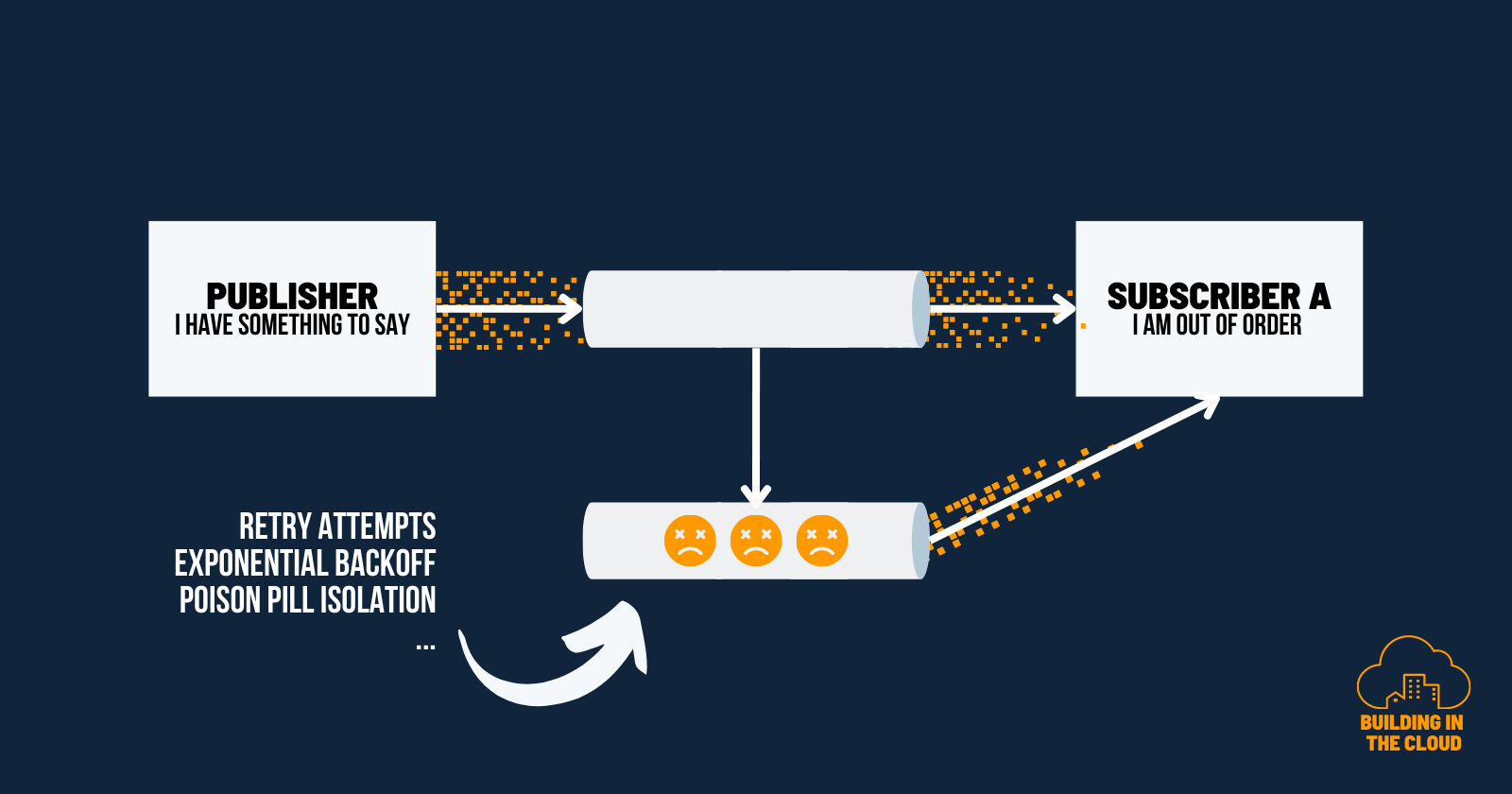
Just because we have a dead-letter channel doesn't mean our system is capable of handling message retries. The missing part is connecting the original message recipients with the dead-letter channel once they can process them.
Effective retry mechanisms in messaging systems require careful consideration and adherence to best practices. Here are some key considerations and strategies to help you handle retries successfully. A lot of these strategies can be implemented with Amazon Eventbridge and Amazon SNS dead-letter queue features.
Key Considerations for Implementing Retries
Identify failure scenarios: Understand the potential reasons for message delivery failures, such as network issues, temporary service unavailability, or exceeded throughput limits. Identifying these failure scenarios allows you to design appropriate retry mechanisms.
Define maximum retry attempts: Determine the maximum number of retry attempts for a failed message. Setting a limit prevents infinite retries and ensures that processing moves forward after a reasonable number of attempts.
Strategies for Retry Policies and Exponential Backoff
Exponential backoff: Implement an exponential backoff strategy where the delay between retries increases exponentially with each subsequent attempt. This approach helps avoid overwhelming downstream systems during transient failures and improves the chances of successful retries.
Jitter: Introduce jitter by adding randomization to the retry timings. This randomization further reduces the likelihood of congestion during retry attempts and helps distribute the load more evenly.
Monitoring and Troubleshooting Retries
Monitor dead-letter channels: Regularly monitor the dead-letter channels to identify patterns or recurring issues that may be causing message delivery failures. Analyze the messages stored in the dead-letter queues to gain insights into the root causes of failures and take appropriate corrective actions.
Logging and error reporting: Implement comprehensive logging and error reporting mechanisms to capture and record detailed error information during retries. This data is valuable for error analysis, debugging, and identifying areas for improvement.
Handle Poison Pill Messages
Identify poison pill messages: Poison pill messages are messages that repeatedly fail during processing. Detect and identify these messages to prevent them from entering infinite retry loops.
Move poison pill messages to a separate queue: When a message repeatedly fails a predefined number of retries, consider moving it to a separate queue for manual inspection and handling. This prevents the message from continuously being retried, preserving system resources.
Conclusion
We have explored the importance of handling retries in messaging systems and discussed various strategies and best practices to enhance the reliability of message processing. We started by understanding the role of publish-subscribe channels and message brokers in messaging systems. We then delved into the significance of dead-letter channels as a mechanism to handle failed message deliveries.
We explored how dead-letter channels can be implemented with Amazon SQS integrated into popular AWS services such as Amazon SNS and Amazon EventBridge. By leveraging the power of Amazon SQS dead-letter queues, we can capture and analyze failed messages, allowing for retries and resolution of delivery issues.
Furthermore, we discussed key considerations for implementing retries, including identifying failure scenarios, defining maximum retry attempts, and establishing appropriate timeout thresholds. We highlighted the importance of exponential backoff and introduced strategies to prevent infinite loops when dealing with poison pill messages.
Handling retries in messaging systems requires a thoughtful approach and an understanding of the potential failure points within your architecture. By following the best practices outlined in this article, you can improve the reliability of your event-driven systems, reduce message processing failures, and provide a robust and resilient experience for your users.